A language without a teacher
Woccon was historically spoken by the Waccamaw people. Today it is dormant — there are no fluent speakers to learn from, only the scholarship that survives. For someone who wants to learn it, that scholarship is the entire teacher: scattered transcriptions, comparative notes, and reconstructions written for linguists, not learners.
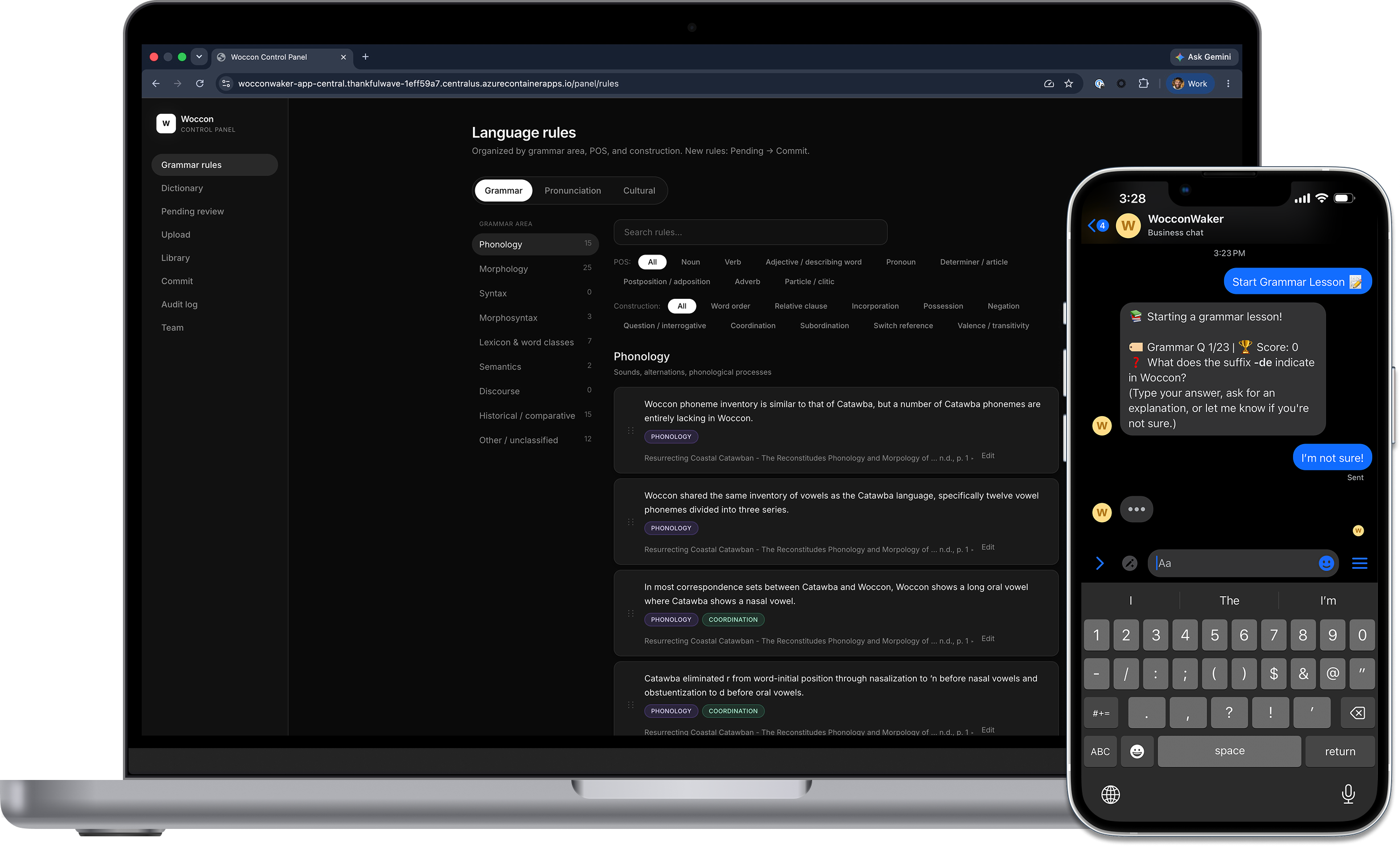
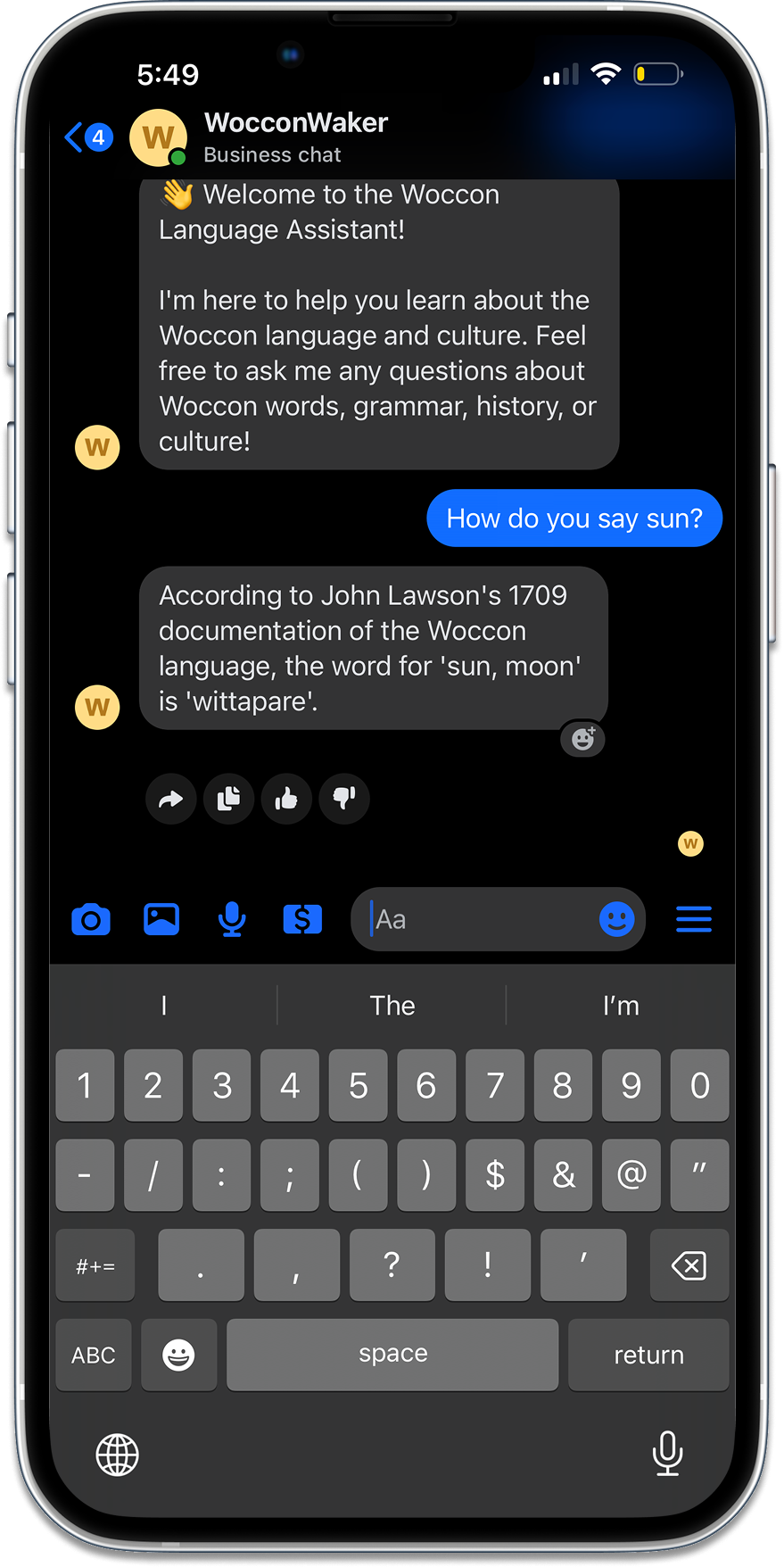
Learning a dormant, low-resource language purely from that material is, for most people, too confusing to attempt. The knowledge exists, but it isn’t accessible. WocconWaker was built to close that gap — to turn raw scholarship into something a person can actually ask questions of.